
RE: I began writing this mid-September when @XEng open-sourced the core algorithm behind the For You feed. What I saw was a ton of Scala code with highlight being grok integration as basis for semantic recommendation.
How it looked like (post September patch):
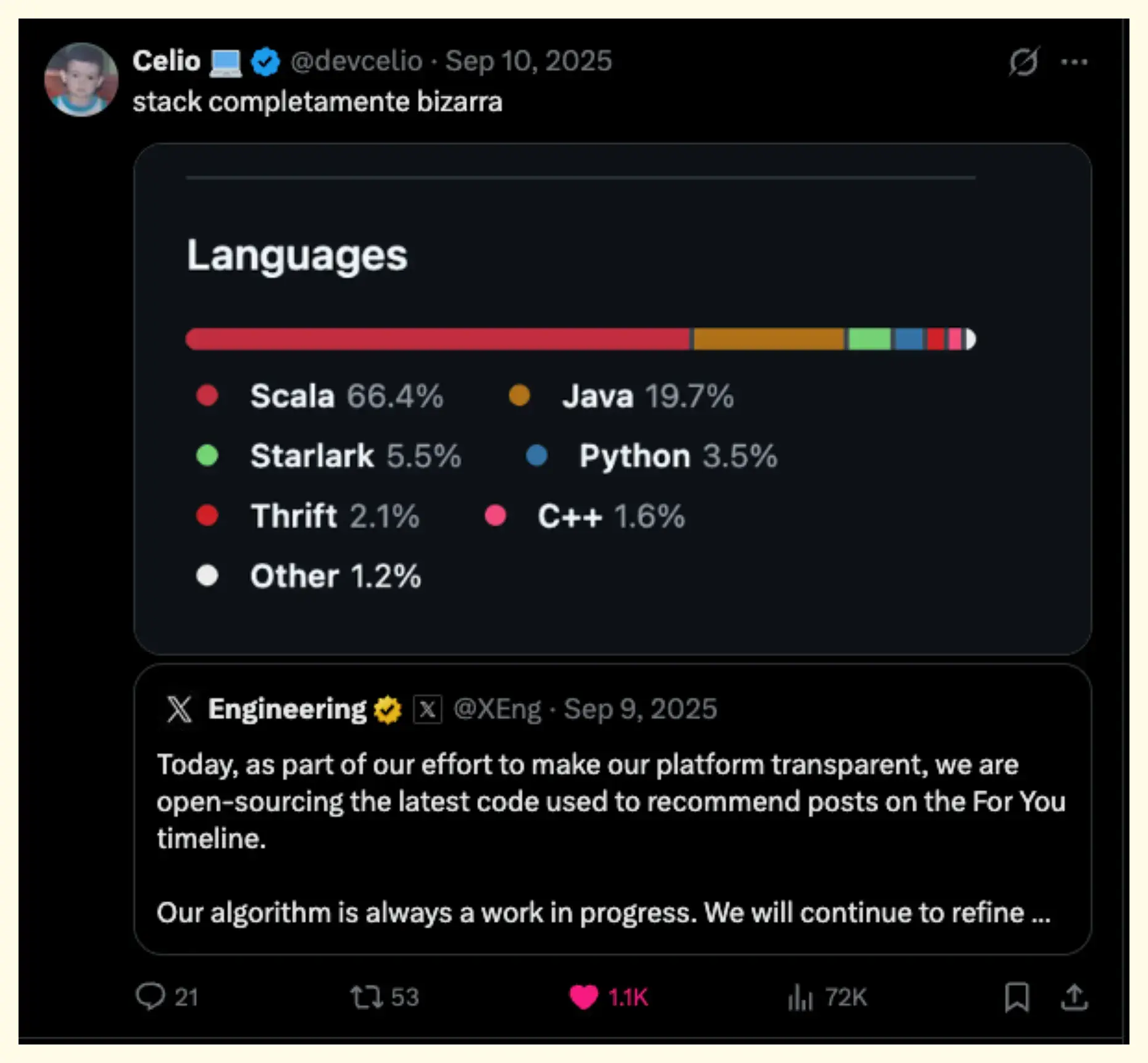
I was expecting a blogpost from the team on the selective update but it never came. Looking back, I admit it wasn’t a bad decision to not jump to premature conclusions based on idiosyncratic explanations about the [+65k lines] refactor.
Now it looks like:

The new algorithm is a complete architecture rewrite in Rust/Python, moving from the legacy Scala/Java stack that was heavily reliant on heuristics and hand-crafted features. The Retrieval stage now uses a two-tower model–”user” tower and “candidate” tower, to find relevant posts to show. This is faster and more feature-rich method than earlier graph-based approach used by Twitter.
After selecting posts the user might engage with, next comes the Ranking stage that decides the order in which these relevant posts appear in the timeline. The old algorithm used a two step ranking: LightRanker and HeavyRanker. This is now offloaded to Grok (Code: x-algorithm/phoenix/recsys_model.py).
# x-algorithm/phoenix/recsys_model.py
# The model takes a sequence of your history and predicts your next action
def call(self, batch, recsys_embeddings):
# combines user history + posts into one sequence
embeddings, ... = self.build_inputs(batch, recsys_embeddings)
# Transformer processes the sequence
model_output = self.model(embeddings, ...)
# predicts logits for actions (Like, Reply, Repost)
return RecsysModelOutput(logits=logits)
Use of transformers is common among companies building recommendation systems for search, retrieval, or ads. An interesting detail from the algorithm is how they implement candidate isolation in Phoenix Scorer Ranking with attention mask. The inputs i.e., user and candidate (tweet) features, are projected onto a matrix prior to self-attention. This is essentially a lower-triangular mask or tril (as Karpathy calls it) with a slight modification to make sure the model’s score for a post is independent of other posts in the batch. Documentation explains this using a diagonal only matrix.
Anyways, I am thinking why the intermediate refactor? Why did they choose Scala, only to rewrite in Rust (cliché) four months down. So I asked Gemini for plausible explanations: (I am too lazy to rewrite in my own words)

This is just the core Ranking and Retrieval algorithm and the team will release more in the coming weeks along with developer notes.
-
To know more about two-tower architecture: The Two-Tower Model for Recommendation Systems: A Deep Dive
-
See how other companies are using transformers in their recommendation systems: YT
Something I'd love to see at this scale:
When twitter was launched in 2006, it was the intention of their creators to make it serve as a permissionless social media protocol. People could come and build their apps and businesses off on the Twitter protocol and benefit from the openness of the API. This early openness fostered a vibrant ecosystem of third-party applications, especially in the early years, when many people used Twitter as a protocol and not just a centralized social media platform. Over time, however, this slipped down the company’s priority.